需求
最近再做扫码识别,为了降低错误率,我就用了一个高阶算法,用 1 秒时间采样了大概100 多条输出结果(节流),然后取出其中重复项最高的,进行容错,提高准确率。
let a = ['aaa', '2012', '2012', '2013', '2014', '2012', '2014'];
mode(a); // 2012
实现
网上抄的一个快速的,未优化的解决方案。复杂度 O(n)。
let a = ['aaa', '2012', '2012', '2013', '2014', '2012', '2014'];
function mode(array) {
if (array.length == 0) return null;
let modeMap = {};
let maxEl = array[0],
maxCount = 1;
for (let i = 0; i < array.length; i++) {
let el = array[i];
if (modeMap[el] == null) modeMap[el] = 1;
else modeMap[el]++;
if (modeMap[el] > maxCount) {
maxEl = el;
maxCount = modeMap[el];
}
}
return maxEl;
}
mode(a);
也是网上抄的,写起来比较快,但是性能不好,我当时随手选的
function mode(arr) {
return arr
.sort(
(a, b) =>
arr.filter((v) => v === a).length - arr.filter((v) => v === b).length
)
.pop();
}
mode(['pear', 'apple', 'orange', 'apple']); // apple
网上抄的简单易懂的解决方法
let a = ['pear', 'apple', 'orange', 'apple'];
let b = {};
let max = ''
let maxi = 0)
for (let k of a) {
if (b[k]) b[k]++;
else b[k] = 1;
if (maxi < b[k]) {
max = k;
maxi = b[k];
}
}
群友 Pomo 和 safa 写的
function mode(list) {
var map = {};
var bigger = {
name: null,
count: 0,
};
let i = 0;
let llen = list.length;
for (i = 0; i < llen; i++) {
if (list[i] in map) {
map[list[i]]++;
} else {
map[list[i]] = 1;
}
if (map[list[i]] > bigger.count) {
bigger.count = map[list[i]];
bigger.name = list[i];
}
}
return bigger.name;
}
var list1 = ['aa', 'bb', 'asd', 'dd', 'aa', 'dd', 'dd', 'dd', 'dd'];
// var list3 = new Array(100*10000).fill(null).map(()=>parseInt(Math.random()*26).toString(36))
let loop_times = 10 * 10000 * 0;
console.time();
// for(let i = 0; i < loop_times; i++) mode(list1)
mode(list1);
console.timeEnd();
function mode1(list) {
return list.sort()[list.length / 2];
}
console.time();
// for(let i = 0; i < loop_times; i++) mode1(list1)
mode1(list1);
console.timeEnd();
function mode2(arr) {
return arr
.sort(
(a, b) =>
arr.filter((v) => v === a).length - arr.filter((v) => v === b).length
)
.pop();
}
console.time();
// for(let i = 0; i < loop_times; i++) mode2(list1)
mode2(list1);
console.timeEnd();
她写的 mode 方法 和上面的第一个 mode 方法是一样的,复杂度 O(n),算是优解
mode1 方法非常有意思,排序后取中间的,如果是 1 1 1 1 1 1 1 1 2 2 3 3 这样的数据集,其中的 1 非常多,那么拿到的结果也是对的
后记
群友参与了讨论,给了不少思路,非常有意思,收获很多,感谢!
有个群友说他用了 100 万条数据进行测试,我们当时就感兴趣了,他贴出了代码
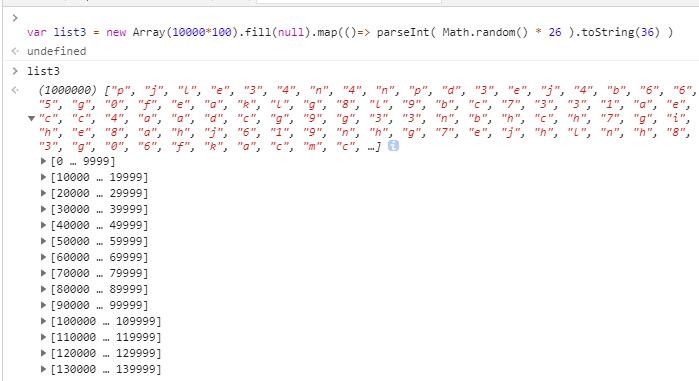
然后就是看到

我当时特别感动,好在代码是我从网上扒拉的。从上面的对比中也看出了算法的重要性。程序的核心就是算法,这句话是没错的。